

Создание голосовых моделей для искусственного интеллекта становится все более актуальной и захватывающей областью разработки. Голосовые ассистенты, речевые технологии и синтез речи играют важную роль в нашей повседневной жизни. В этой статье мы погрузимся в мир создания собственных голосовых моделей для ИИ, исследуя техники и инструменты, необходимые для этого захватывающего процесса.
Приступим к реализации:
Первым шагом нам необходимо выгрузить несколько аудиодорожек, из которых будем вырезать голос и использовать для тренировки ИИ. Для этого можно использовать данный сайт, если Вы желаете брать материал с Youtube:
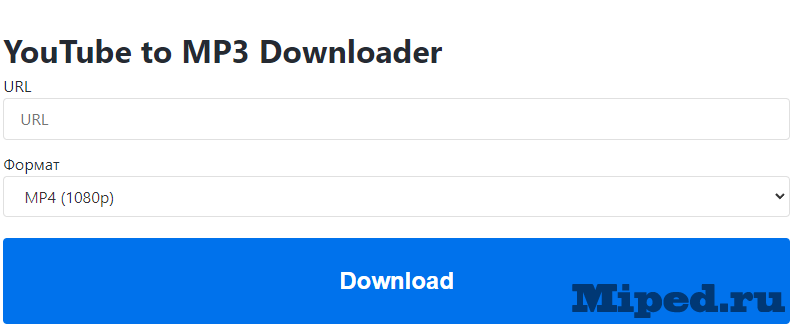
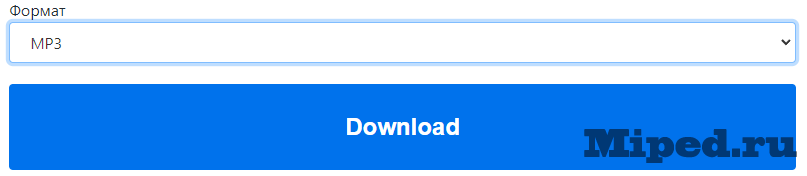
Вставляем ссылку и выбираем формат MP3, загружаем. В общем нужно около пятнадцати минут чистого голоса:
Если Вы использовали музыку, то нужно отделить голос. Для этого переходим на Github и загружаем приложение :
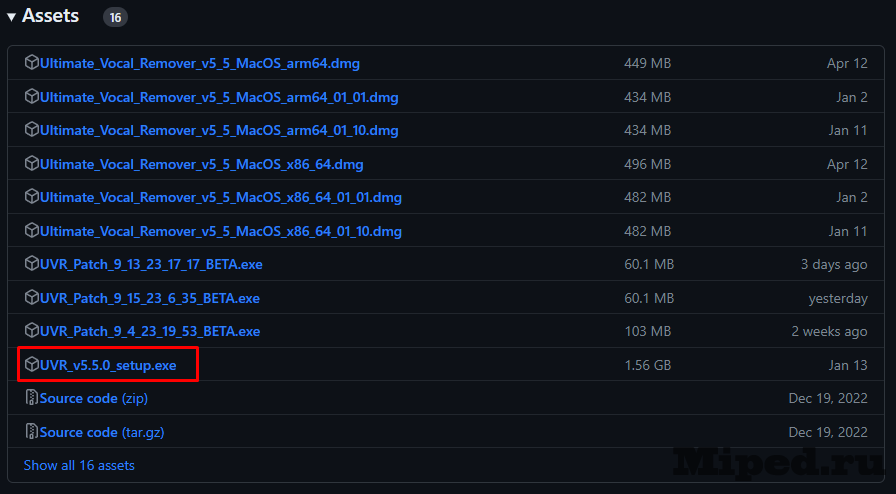
Запускаем его и переходим в настройки:
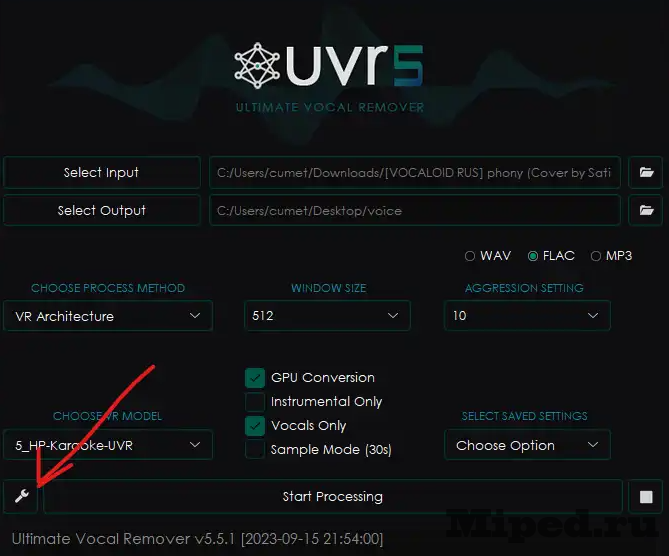
Повторяем все действия, указанные на скриншоте ниже. Нажимаем на большую кнопку для загрузки:
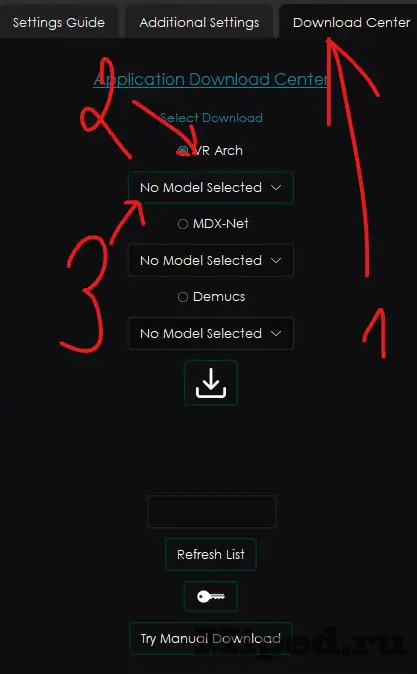
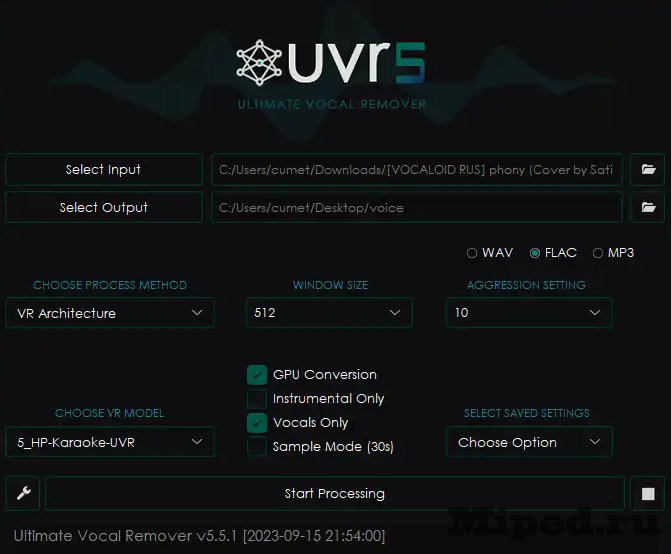
Во вкладке "Select input" выбираем все наши аудиодорожки в MP3 формате; "Select Output" — указываем путь, по которому будут сохранятся итоговые результаты; "Choose Porcess Method" выбираем "VR Architecture". Формат готового файла должен быть FLAC, указываем его. В "Choose VR Model" выбираем модель, указанную на скриншоте ниже. Отмечаем пункт "Vocals Only", пункт "GPU Conevrsion" активируем в зависимости от своей видеокарты. Запускаем процесс:
Склеиваем все свои аудиодорожки в единую, используя любое приложение, к примеру FL Studio. Далее загружаем Audacity и устанавливаем:
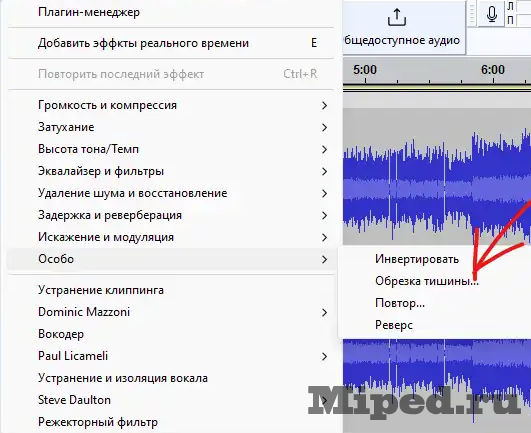
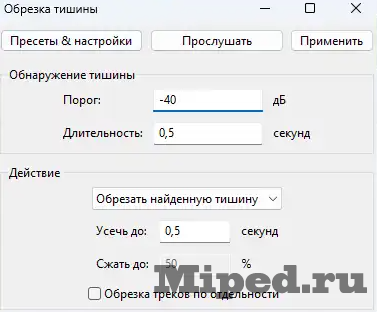
Нажимаем "Выделить" в левом нижнем углу, выбираем сверху "Эффекты" и переходим к обрезке тишины:
Повторяем все настройки со скриншоте ниже и обрабатываем дорожку:
Переходим к тренировке искусственного интеллекта, первым делом загружаем .bat с Github. Создаем папку, помещаем туда файл и запускаем его. После установки находим папку под названием "datasets" и вставляем обработанный файл из Audacity. После этого запускаем "go_web.bat", переходим во вкладку "Train":
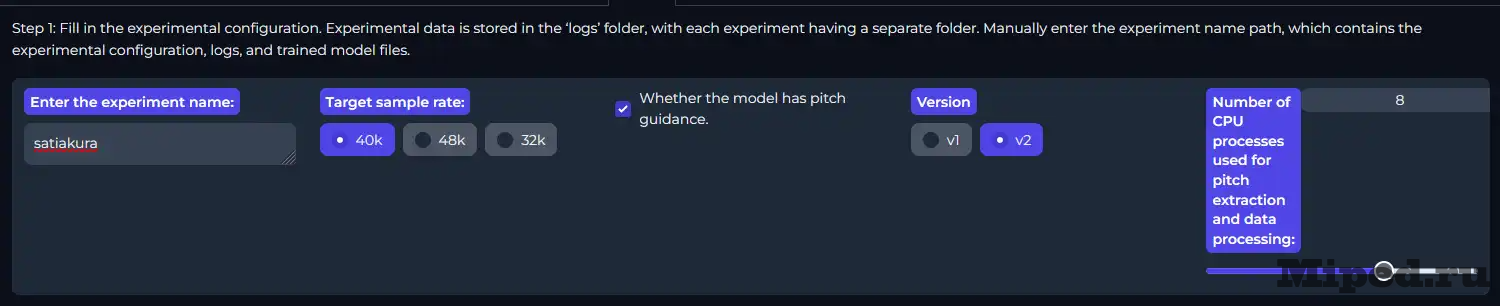
В самом левом поле указываем название модели, запомните его, ведь если процесс обучения прервется — по названию можно будет продолжить. "Target sample rate" выбираем 40k и указываем вторую версию, остальное не трогаем:
В первой графе указываем путь к "datasets", если автоматически не определилось. Нажимаем на "Process data" и ожидаем "end preprocess" в правой части экрана:

Выбираем на какой видеокарте будет происходить тренировка и указываем алгоритм "rmvpe". Кликаем на большую кнопку и ждем "all-feature-done" в окне с информацией:

Выбираем, как часто будет сохраняться результат тренировок, 10 — оптимальный вариант. Общее количество желательно указывать в диапазоне от 250 до 300. В "Batch size per GPU" указываем количество видеопамяти, нажимаем кнопку "Train feature index":
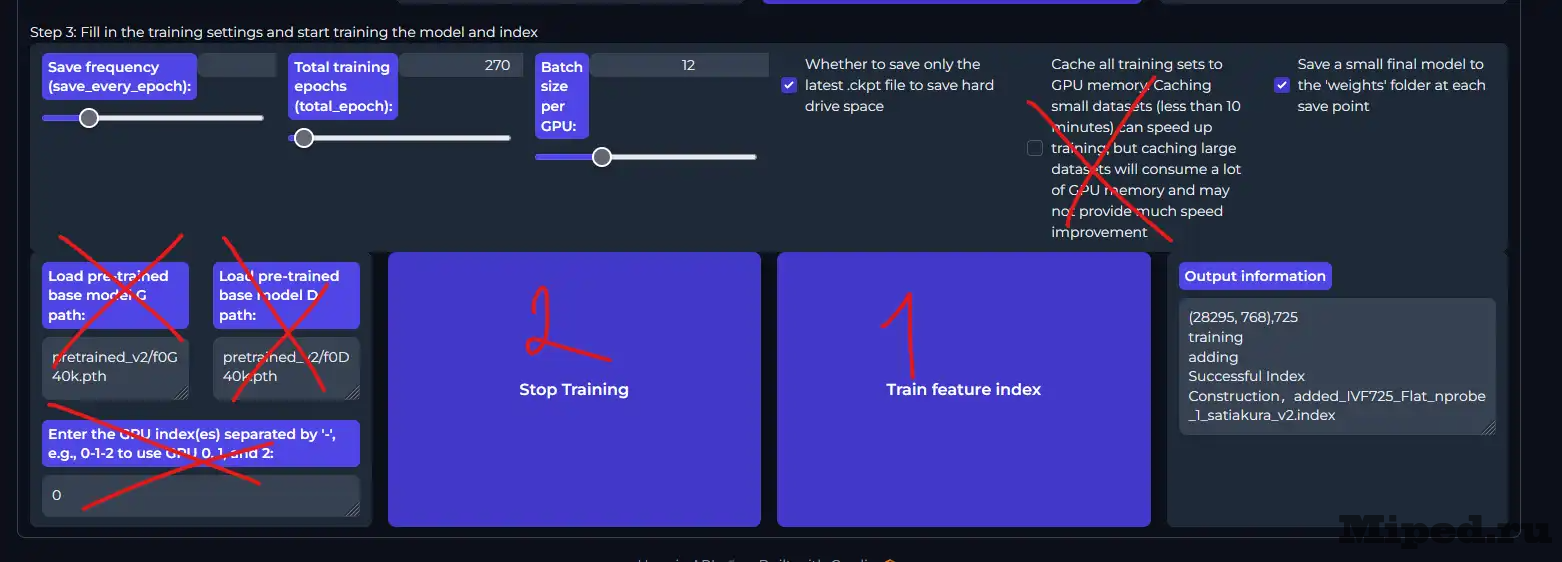
Все готово, начинаем процесс тренировки, используя "Start Training". В командной строке будет выводится вся информация, не закрываем ее, иначе работа остановится:
После окончания процесса необходимо зайти в корневую папку и найти "weights", где нас интересует файл с названием нашей модели и числом эпох в середине. Создаем папку в любом удобном месте и перемещаем его туда:

Возвращаемся в корневую папку и переходим в "logs", открываем папку с названием своей модели. Находим файл с расширением .index, копируем его и вставляем рядом с предыдущим:

На этом все, модель можно использовать для изменения голоса или генерации каверов!


Посетители, находящиеся в группе Гости, не могут оставлять комментарии к данной публикации.