

В наше время возможности искусственного интеллекта расширяются с каждым днем, и это открывает новые горизонты в области автоматической обработки различных данных. Одной из интересных разработок в этой области является нейронная сеть Whisper JAX от компании OpenAI. С ее помощью теперь можно легко получить текст из любой аудиодорожки всего за несколько кликов. В данной статье мы рассмотрим, как работает этот сервис и как его можно использовать.
Приступим к реализации:
Открываем страницу проекта на Hugging Face, используя прямую ссылку и ожидаем небольшой загрузки:

После загрузки сверху можно выбрать один из доступных источников для обработки аудиодорожки. Можно использовать микрофон, готовый аудиофайл или URL—адрес, ведущий на Youtube видео:

К примеру, воспользуемся загрузкой с файла. Нажимаем, чтобы указать путь до необходимого файла или же просто перетаскиваем его в специальное окно:

Выбираем одну из задач, в нашем случае это "transcribe". Помимо этого можно добавить временные метки, для этого ниже есть специальная галочка:

Опускаемся еще немного ниже и нажимаем на кнопку "Исполнить". Ожидаем, время будет зависеть от величины вашего аудиофайла и загруженности сети:

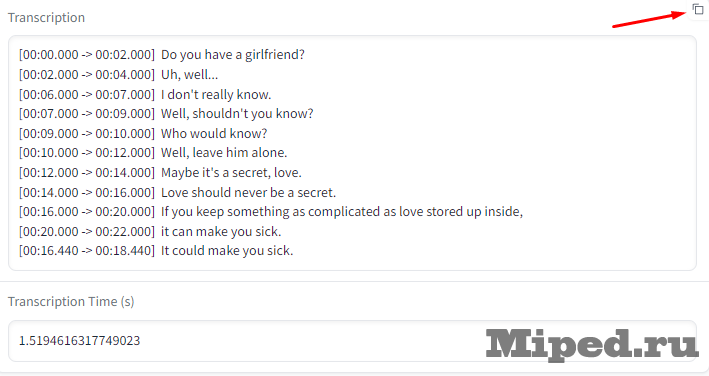
После этого получаем готовую транскрипцию, которую можно сразу же скопировать, используя кнопку в правом верхнем углу:
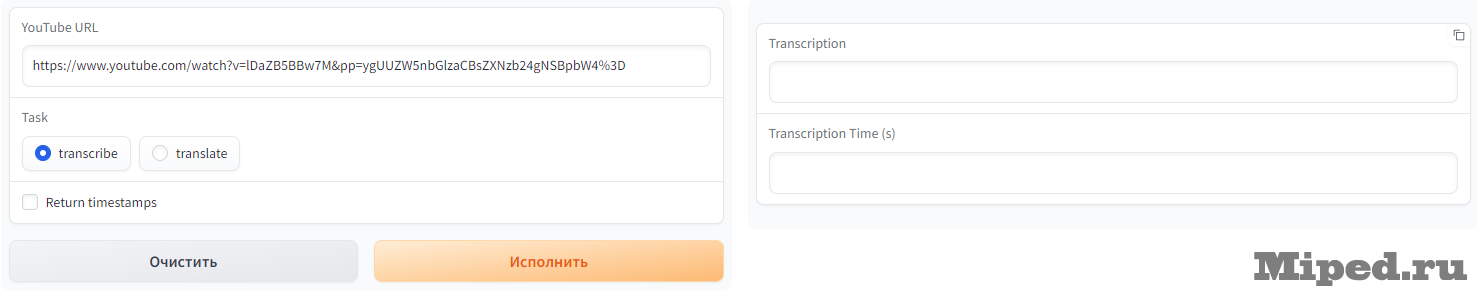
Процесс с Youtube видео не сильно отличается, вставляем ссылку и повторяем те же действия:
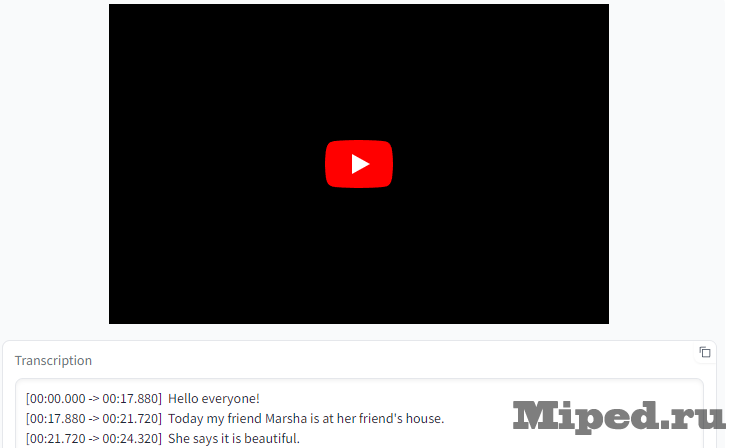
Справа получаем итоговый результат с временными отметками, если они были Вам необходимы:
На этом все, надеюсь статья оказалась для Вас полезной!


Посетители, находящиеся в группе Гости, не могут оставлять комментарии к данной публикации.